
StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
StreamKV 核心逻辑拆解
> [STATUS::OK]:: Baseline model LLaVA-OneVision selected.
> [ENV::INFO]:: Running on NVIDIA H20 GPU (96G).
Step Streaming Encoding
核心挑战: 如何解决流视频内存装不下的问题?
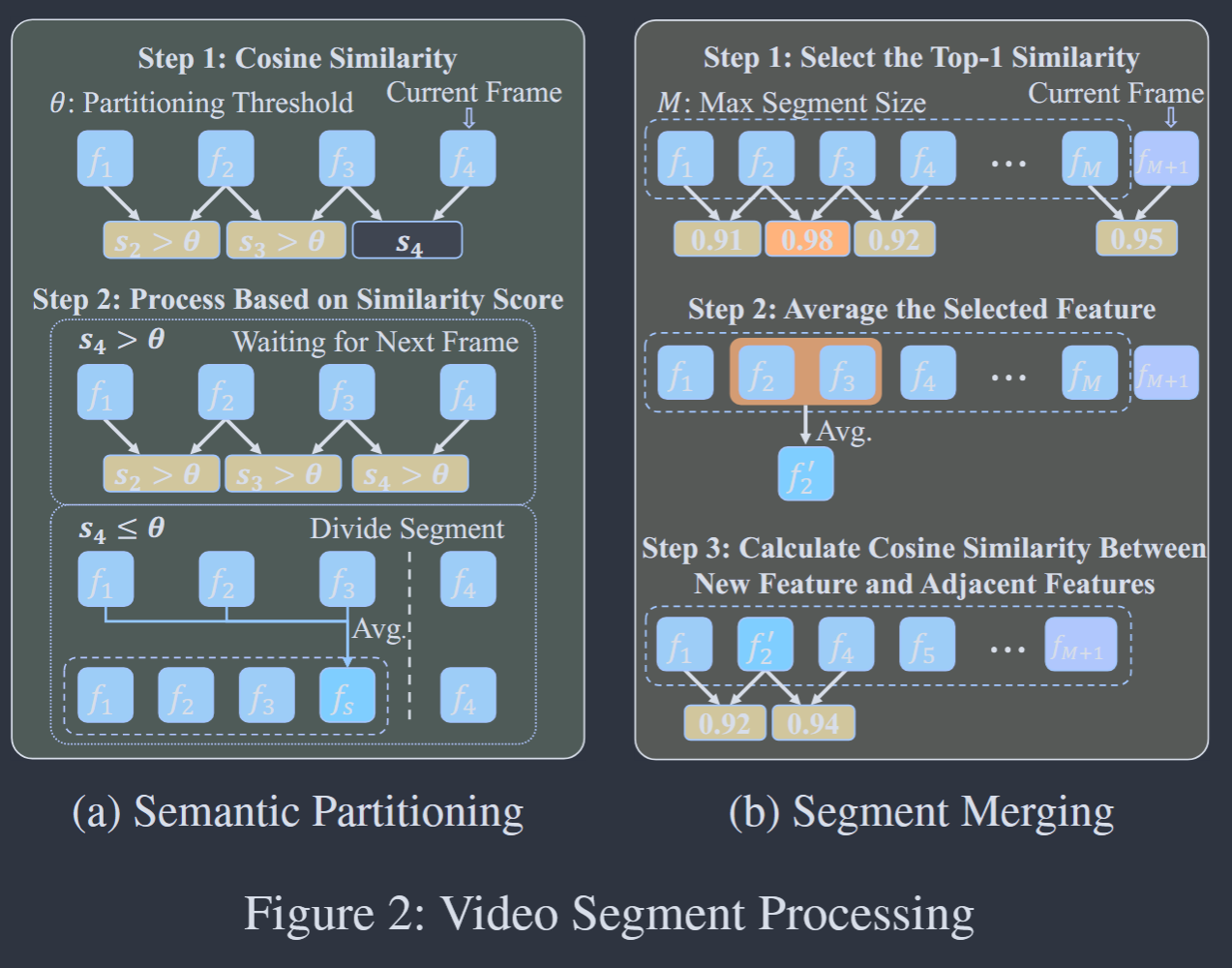
1.1 语义分块与压缩原理 (Semantic Partitioning)
视频是由许多帧组成的,对于输入的每一帧,我们利用 ViT,压平映射,形成一个 f_{im} 向量。通过计算相邻帧的余弦相似度,我们可以判断视频的语意连贯性。
在切割 segment 片段时:
- 切割判定:
Simi(j) 用来计算 f_{j-1} 与 f_j 的余弦相似度。- 高于阈值:保持。
- 低于阈值:切割。
- 溢出保底:
如果 segment 长度已经超过了规定的最长的长度,则将之前余弦相似度最高的两帧相合并,继续添加(这就是 Semantic Partitioning)。
这个 segment 中所有的 f_{im},暴力取平均,就得到了这个 segment 的特征向量 f_{is}(这就是 Summary Vector),保留在显存的特定位置处。
1.2 向量集合 definition 与 Layer 构建
# [SYSTEM::MEMORY_MAP]:: Define Core Vector Sets
rim:
type: k_retrieval_vector
desc: 将第 m 帧的 k 压平、线性映射之后的高维向量(先切碎再合并)
fim:
type: image_pixel_vector
desc: 图像切割压平后的向量,完整保留原图像像素信息
bim:
type: frame_kv_collection
desc: fim 与 $W_k$, $W_v$ 相点积,包含所有 KV 的高维矩阵
note: >
Formula: $b_{im} = [(k_{im,p}, v_{im,p})] | P^2, p=1$
注:完整地、没有 attn 的保存了这一帧的所有内容
fis:
type: segment_summary_vector
desc: 一个 segment 中所有 fim 取平均(attention pooling)
bis:
type: segment_kv_block
desc: fis经过线性映射而来,非从 bim 中提取
constraint: 每一个 segment 只有一个 bis 的 KV block(必须保存)
Bil:
type: frame_bim_stack
desc: 每一帧 bim 的堆叠(不做运算),是之后要不断地删除的原始全部数据
Ril:
type: frame_rim_stack
desc: 每一帧 rim 的堆叠(不做运算)
构建 Layer 时,根据每一层不同的需求设置不同的 W_{k,l} W_{v,l}。每层中所有的 f_{is} 经过 W_k W_v 的线性映射,聚类表示语义相近,明确不同性质。到现在,我们实现了视频编码,但由于内存有限,我们仍需优化。
1.3 内存优化与层自适应 (Layer-Adaptive)
引入 guidance prompt ,较为全面的包含了重要的内容取向。由于每一行设置的 g_l(第 l 层的 guidance)也不同,通过每一行的 g_l 与(r_{is,l} 和 r_{im} 构成的集合)计算余弦相似度,得到一个 L 层的余弦相似度值,并进行降序排列。
- 预算设定: 设定压缩率 θ,计算可保留空间 N = (1 - θ) · T · L。
- 分配逻辑(Layer-Adaptive):
我们设置一个阈值 p ,在每一层(已降序排列)计算最小前缀和使得 sum >= p,计算 l 层总共需要分配的大小,再不断地调整 p (binary search)。
这样做原因是:如果相似度高,说明那一帧对于这个问题而言信息密度高;而若相似度低,则需要更多的帧数来保证信息的全面。
这样提取到最有价值的帧索引集合 I_l,构建出 KVBank。提取的过程是在这些 layer 之外再构建一个 B_l, R_l,不断地 append(不做运算)。
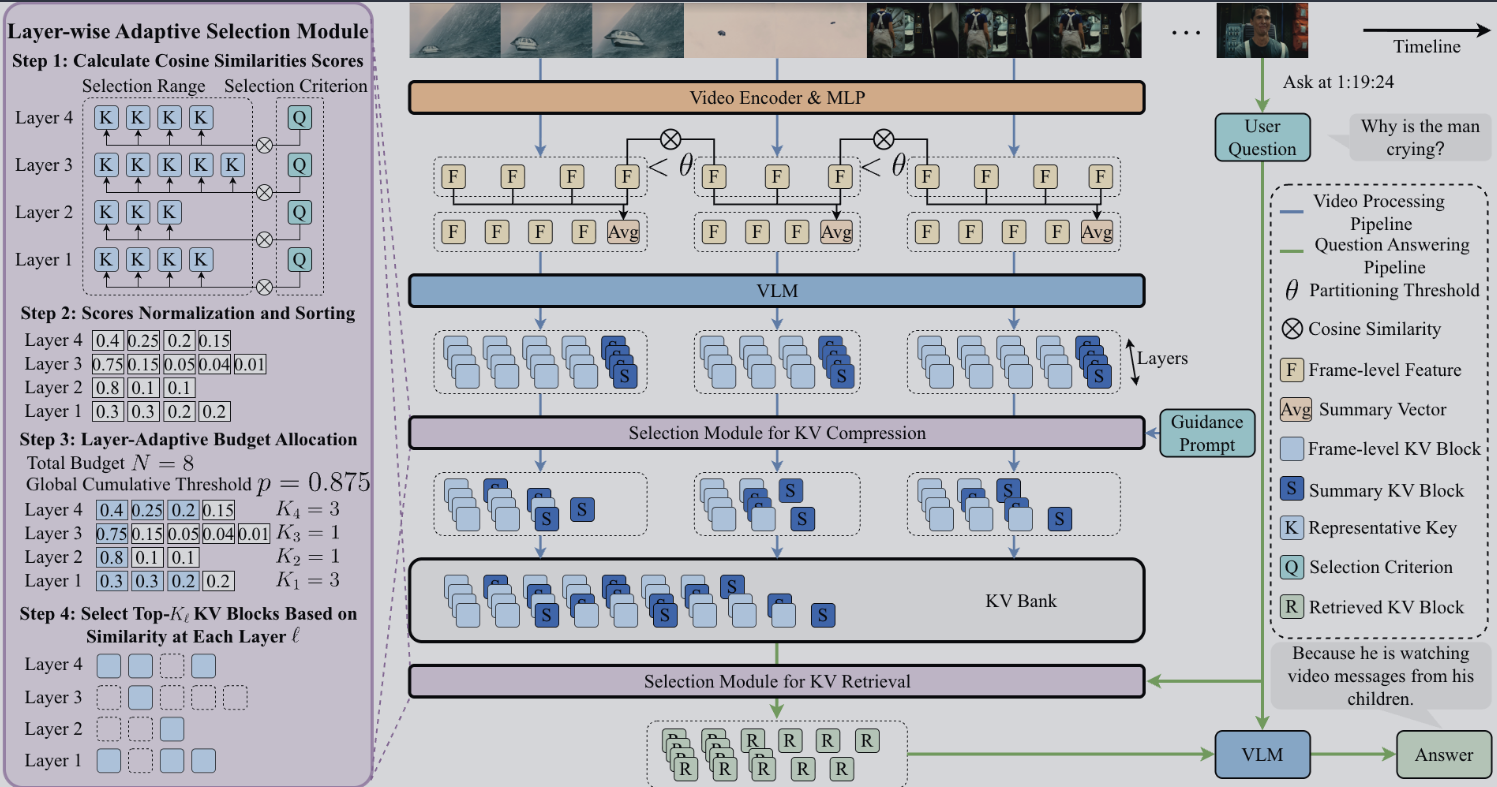
Step 如何根据用户提问检索视频?
此时模仿构建 KVBank 的逻辑:
- 我们不用 guidance prompt 而是用用户输入的问题作为 g_l 计算相似度。
- 关于如何将用户输入转化为高维向量聚类:
- 拆解问题为 token -> 查表映射。
- 以同样的方式检索到与用户问题最为相关的几帧,提取。这就是 Precise Retrieval。
Step 如何生成回答
与之前 RoPE 的“随着时间间隔延长,语义相关性衰减”不同,StreamKV 将这几帧连起来处理,保证语义的连贯,不会丢失细节。
参考之前输出的 token、提取的内容、用户的输入,计算 cross-attn来预测应该输出什么。
论文实验部分
(由于是刚刚接触,不求甚解)
- 从 0.5 FPS 的采样速率我们看到,必须通过采样来降低系统负荷。
- 我们需要交代清楚运行的环境,达成实验的可重复性。
等等,证明了 StreamKV 的效果极佳。
消融实验 (Ablation Studies)
消融实验是做什么的:
通过“控制变量法”,证明论文提出的每一个新功能(语义分块、总结向量、层自适应)确实都是有用的。